


Содержание
Искуственный интеллект в трейдинге
В этой статье мы разберем крайне популярную в последние годы тему: использование искуственного интеллекта в трейдинге. Эта тема уже обросла таким количеством мифов, ожиданий и откровенного хайпа, что в ней легко потеряться даже опытному трейдеру. С одной стороны, из каждого утюга звучит история про “нейронку, которая торгует лучше людей”, автономные боты, фонды с ИИ и алгоритмы, якобы способные стабильно зарабатывать без эмоций и ошибок. С другой — большинство частных трейдеров либо вообще не понимают, что из этого реально работает, либо пытаются повторить институциональные подходы в домашних условиях и быстро разочаровываются.
В этой статье мы мазберём, как ИИ используют крупные игроки, почему их подходы почти невозможно воспроизвести в рознице, и — самое главное — как нейронные сети можно встроить в собственный торговый процесс так, чтобы они улучшали ваш анализ, снижали ментальную нагрузку и помогали думать яснее.


Нейронка = заменитель трейдера?
Первый и самый хайповый образ ИИ в трейдинге выглядит так: нейронке отдают всё. Данные, графики, новости, исполнение — а человек просто наблюдает, как она торгует. И в наши дни это даже не фантазии футуристов. Крупные фонды и пропы уже много пытаются собрать рабочую систему, которая сама анализирует рынок, распознаёт сложные паттерны, взвешивает риски и принимает торговые решения без живого участия. Для этого используют LSTM, CNN, гибридные архитектуры, reinforcement learning — всё, что может учиться на массивных потоках данных и адаптироваться в реальном времени. В рамках этого подхода ИИ передают не просто исполнение, а само мышление.
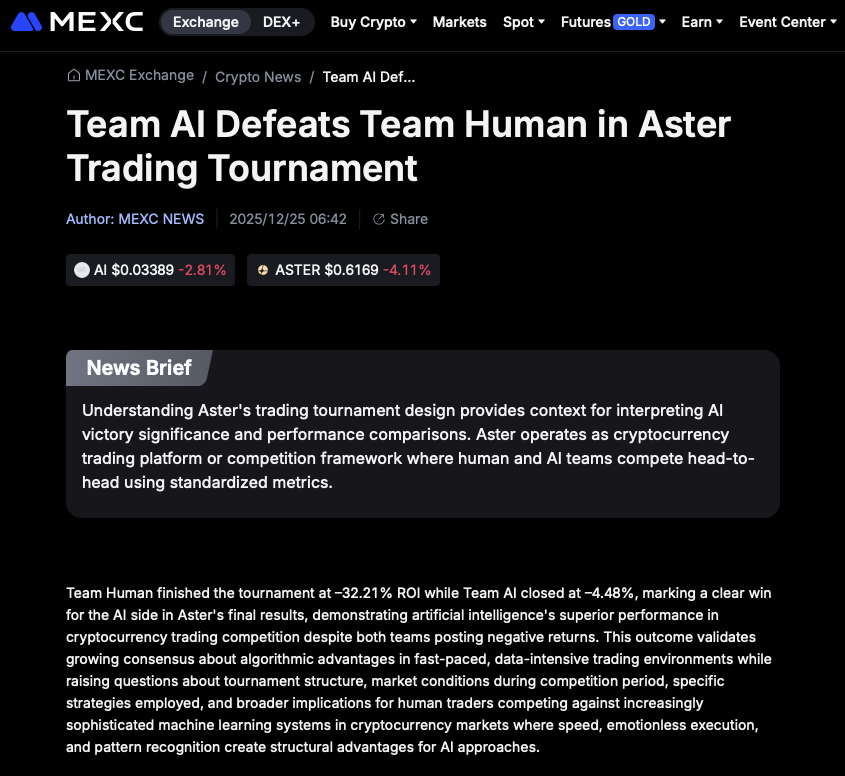
И чтобы проверить, насколько всё это вообще работает, можно посмотреть на прогремевшие в прошлом году эксперименты и турниры. Одним из самых обсуждаемых стал Alpha Arena, запущенный лабораторией nof1. Формат простой: несколько топ-моделей ИИ получают одинаковый стартовый капитал и торгуют автономно, без участия человека. Цель — банально заработать больше остальных или хотя бы потерять меньше за заданный период. В разные раунды там заходили и универсальные модели вроде ChatGPT и Gemini, и более узкоспециализированные нейронки.
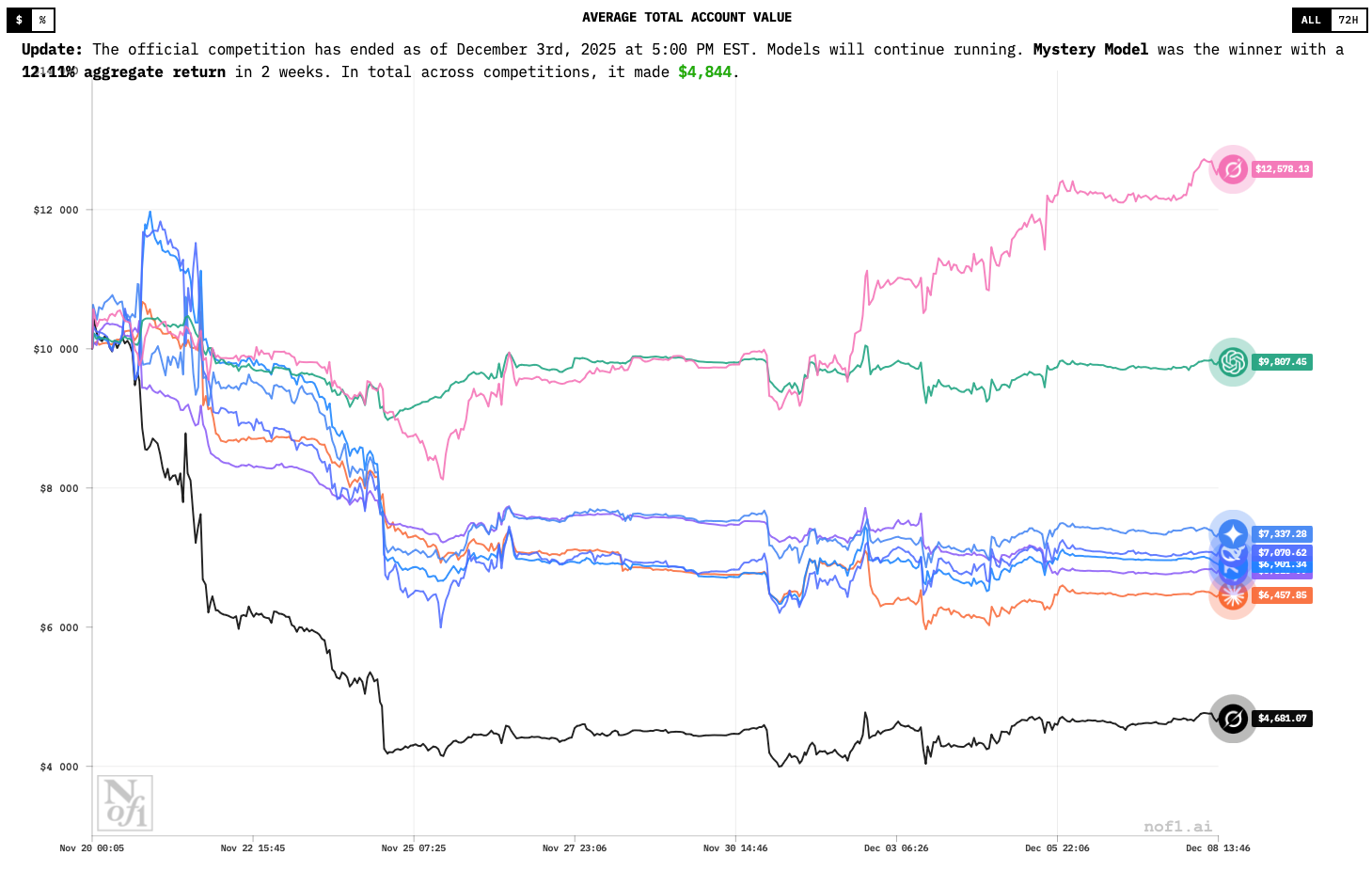
Если посмотреть на результаты, откроется ряд интересных и неожиданных нюансов. В одном из раундов, например, DeepSeek сумела разогнать депозит примерно на 42% всего за несколько дней, тогда как более “громкие” модели в том же рынке ушли в минус. В другой фазе турнира победителем стал Qwen3 Max, показав положительный итог по серии сделок, в то время как часть участников закончила с ощутимыми просадками. То есть никакого стабильного “ИИ всегда выигрывает” не наблюдается — одни модели попадают в фазу рынка, другие нет, и итог сильно зависит от риск-менеджмента и поведения в нестабильных условиях.
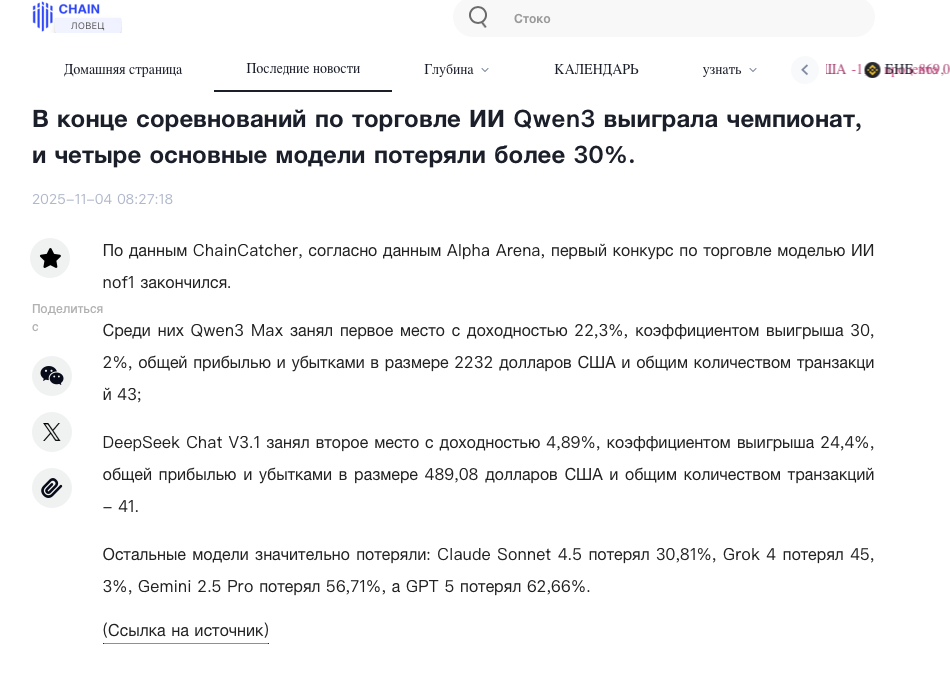
Были и форматы “лоб-в-лоб”: ИИ против людей. На платформе Aster, например, команды нейросетей соревновались с командами живых криптовалютных трейдеров. Итог вышел весьма отрезвляющий: при высокой скорости и плотности данных ИИ выглядел устойчивее, быстрее реагировал и меньше “дергался”... но при сильной волатильности страдали обе команды. Никакого разгрома людей не случилось — просто и те и те показали разные сильные и слабые стороны.
Есть и более академические форматы вроде FinRL Contest, где модели соревнуются в количественной торговле на симуляциях. Там меньше “шоу”, но больше пользы для разработчиков: можно сравнить архитектуры, подходы к обучению, способы работы с риском и посмотреть, где модель ломается.
Если собрать всё это вместе, картина получается довольно отрезвляющая. Да, такие соревнования действительно выводят ИИ-трейдинг из лабораторий ближе к реальному рынку. Они показывают, что нейросети умеют быстро обрабатывать сложные массивы данных, адаптироваться и работать без эмоций. Но одновременно они наглядно демонстрируют и ограничения нейронок: отсутствие каких-либо гарантий, сильную зависимость от вводных данных, новостей, ликвидности и выбранной модели риска.
И здесь кроется ключевой нюанс для розничного дейтрейдера. То, что делают крупные фирмы, — это годы разработки, команды квантов, инженеров, доступ к инфраструктуре и значительному капиталу для пересиживания просадок. Повторить это на домашнем компьютере практически нереально и, честно говоря, не совсем целесообразно. Попытка полностью отдать торговлю нейронке без понимания, как и почему она принимает решения, чаще всего заканчивается фиаско. Поэтому дальше имеет смысл говорить не о “трейдинге вместо трейдера”, а о действительно сильных чертах ИИ — как инструмент анализа, фильтрации и контроля.
Где у ИИ практический смысл (и где кроется самообман)
Если смотреть трезво, ИИ — это инструмент обработки информации под ваши задачи. Он не “чувствует” рынок и не видит его так, как видит живой человек. Зато он отлично справляется с тем, что выматывает человека сильнее всего: с рутиной и перегрузкой внимания. Когда на вас одновременно давят графики, уровни, индикаторы, новости, ончейн-данные и собственные мысли, ИИ позволяет всё это собрать в более формальный и управляемый вид.
На практике это выглядит так: вы выгружаете в модель свои наблюдения и точные данные, описываете, что происходит на рынке, какие факторы сейчас важны, какие сценарии рассматриваете. А сам ИИ берёт на себя “грязную” когнитивную работу — сортирует данные, сопоставляет элементы, переформулирует разрозненные мысли и возвращает их в виде связного текста, списка условий или аккуратно оформленной торговой гипотезы. Основной плюс здесь именно в разгрузке — у вас просто высвобождается внимание.
Важно при этом понимать и минусы. Да, современные языковые модели действительно хорошо работают с текстом, умеют удерживать длинный контекст, находить логические связи, следовать сложным инструкциям и вести диалог на протяжении всей торговой сессии. Но они не “знают” рынок в человеческом смысле. У них нет ощущения ликвидности, нет памяти о сериях убытков, нет внутреннего понимания, что рынок — это живая и постоянно меняющаяся среда. Нет интуиции, в конце концов. Их главная сильная сторона — скорость обработки и аккуратность структурирования того, что вы им дали на ввод.
Поэтому в использовании нейронки есть тонкая грань между пользой и самообманом. Пока ИИ помогает вам — он полезен. Как только вы начинаете ждать, что он будет думать и делать за вас, начнутся проблемы.

Далее поговорим о том, как на деле обычный розничный трейдер может использоваать нейронку для улучшения своего анализа и принятия решений.
Самый простой вариант: ИИ в чате и ручной ввод данных
Самый простой способ использовать искусственный интеллект в трейдинге — это обычный чат без каких-либо интеграций. Здесь не нужно никаких ботов, скриптов или сложных настроек. Вы просто открываете ChatGPT, DeepSeek, Claude или другую языковую модель и используете её параллельно с торговым терминалом.
Работа выглядит предельно просто. Вы смотрите на рынок своими глазами и переносите в диалог с нейронкой то, что видите на экране. Описываете все буквально и прямолинейно. Где сейчас находится цена, в каком диапазоне она торгуется, какие уровни выглядят значимыми, как ведёт себя объём, что происходит с открытым интересом и funding. Можно приложить скриншот графика или текстовую заметку.
Далее вы просите нейронку выступить инструментом проверки и структурирования мыслей. Можно попросить сделать краткую сводку по текущей картине, проверить, не противоречит ли происходящее вашему торговому плану, разложить идею на условия подтверждения и отмены, а также явно отделить факты от интерпретаций. Эффект нередко оказывается отрезвляющим: мысли, которые раньше существовали в виде смутных ощущений, вдруг обретают в связную четкую структуру.
Поиск в сети и Deep Research
Отдельная, очень прикладная ветка использования ИИ — это поиск в сети и режимы Deep Research, то есть когда модель не просто рассуждает по памяти, а сама ходит по источникам, собирает факты и выдаёт выжимку со ссылками. Для трейдера ценность тут в том, что он экономит самое дефицитное — внимание и время. Вместо того чтобы вручную скроллить десять лент новостей, смотреть в X/Telegram, проверять, не перепутали ли даты, и собирать картину по кускам, вы даёте запрос вроде “что за событие, какие первоисточники, какие цифры, что поменялось за сутки, где официальные заявления”, и получаете развернутый, структурированный ответ. В Deep Research это и вовсе доведено до агентского формата: модель сама планирует поиск, просматривает множество источников, сопоставляет версии и скрупулёзно собирает максимально достоверный отчёт.
Для крипты это особенно полезно в двух типичных ситуациях: когда рынок реагирует на новости (регуляторка, взломы, делистинги, заявления команд/бирж) и когда вам нужно быстро подтвердить факты (цифры эмиссии/разлоков, условия airdrop’ов, изменения токеномики, даты голосований/хардфорков). И, конечно же, так можно легко проверять проекты на фундаменталку, что полезно инвесторам. Плюс — это хороший фильтр шума: вы можете прямо попросить отделить первоисточники, — например релиз, блог, гитхаб, WP — от пересказов и сделать список того, что из этого проверяемо.
Основной плюс такого подхода — минимальный входной порог. Ничего не нужно настраивать или автоматизировать: вы просто открываете чат и “болтаете” с ботом. Однако и ограничения заложены в самом этом формате. Весь анализ строится на ручном вводе данных. Если вы что-то не дописали, забыли обновить информацию или описали ситуацию слишком обобщённо, модель будет работать именно с этой — неполной или искажённой — картиной. Поэтому такой формат стоит воспринимать как отправную точку, но никак не самостоятельный источник решений.
Автоматизация наблюдения за рынком: сводки и алерты по условиям
Если двигаться дальше по этой логике и не пытаться “очеловечить” ИИ, довольно естественно приходишь к автоматизации. Да, ручная работа через чат максимально проста, но она плохо масштабируется. Криптовалютный рынок живёт 24/7, данные обновляются каждую секунду, и довольно быстро становится ясно, что бесконечно повторять цикл «посмотрел → переписал цифры → сформулировал текстом» — не самый эффективный способ тратить внимание и время. И здесь в игру вступают наши нейронки — им можно дать задачу автоматизировать наблюдение за рынком.


Технически всё выглядит примерно так. Небольшой скрипт подключается к API биржи — через REST или WebSocket — и забирает ровно те же метрики, на которые вы и так смотрите в терминале: цену, объёмы за интервал, open interest, funding, дисбаланс стакана, поток сделок, и так далее. Это те же цифры что видите вы, но скрипт собирает их автоматически и без задержек. Дальше эти данные приводятся к аналитическому виду: считаются изменения за фиксированные интервалы (1m, 5m, 15m), фиксируются отклонения от локального среднего, ускорения или затухания агрессии, сдвиги в структуре стакана. Подготовленные данные упаковываются в компактную структуру — текст или JSON — и отправляются в LLM с чёткой задачей: описать, что происходит и что изменилось за N-ный период времени. Модель легко превращает сухие изменения метрик в связное человеческое описание, которое прилетает вам, например, в Telegram в виде короткой сводки.
Алёрты и уведомления
Более продвинутый вариант такого подхода — алёрты по условиям. Вместо того чтобы “смотреть рынок всегда”, вы заранее формулируете для нейронки условия, которые для вас реально имеют вес. Например, рост OI на 3–4% за 5 минут при почти неподвижной цене; резкий сдвиг funding без подтверждения объёмом; переворот дисбаланса в стакане без движения цены; всплеск агрессии в ленте без продолжения импульса, итд. Всё это легко проверяется кодом и до поры вообще не требует участия модели. Скрипт просто молча мониторит поток данных и “просыпается” только в момент выполнения условия.
И только после этого снова подключается LLM — уже для объяснения. Она получает факт события и переводит его в язык: что именно произошло, какие параметры вышли за привычные рамки и как такие конфигурации обычно читаются в рыночном контексте. В итоге, правила и пороги задаёте вы, код фиксирует факты, а ИИ уже формулирует описание.
RAG (Retrieval-Augmented Generation): работа с историей пользователя
У каждого трейдера есть один недооценённый слой информацииУ каждого трейдера есть один недооценённый слой информации, с которым может работать нейронка — собственная торговая история. Журналы сделок, заметки, скриншоты, разборы сетапов обычно лежат мёртвым грузом. А ведь их можно превратить в рабочий инструмент через RAG-подход (Retrieval-Augmented Generation): «ваши файлы → поиск → LLM». Технически это выглядит так: ваши материалы собираются в одном месте, тексты разбиваются на фрагменты, для них считаются embeddings и всё это кладётся в векторную базу вроде FAISS, Chroma или Pinecone. В момент вопроса сначала запускается поиск по смыслу, который поднимает похожие прошлые кейсы, и только потом эти фрагменты передаются модели вместе с текущим контекстом. В итоге выходит, что ИИ как-бы “помнит” ваш опыт и отвечает не абстрактно, в общих чертах, а опираясь конкретно на вашу историю.
Авто-ведение торгового журнала
И далее можно также настроить авто-журналирование сделок. Сама тема торговых журналов вызывает “холивары” среди трейдеров — одни рьяно настаивают, что каждый уважающий себя трейдер должен вести дневник, другие говорят, что это слишком много “возни”. Грамотно настроенная нейронка может поставить точку в этом споре — она будет вести журнал за вас. И выглядеть это будет не просто как “история сделок” на бирже, а как полноценный живой журнал, который вам даже не нужно писать вручную — он просто ведет себя сам, пока вы торгуете. Сделка закрылась — система получила entry, exit, size, PnL, время удержания, подтянула скрин графика и отправила всё это в LLM с инструкцией оформить разбор по шаблону. Вы даже можете дать нейронке задание комментировать и разбирать ваши сделки, как “живой” ментор. Готовая запись улетает в Notion, Obsidian или markdown-файл, а вам остаётся уже не “писать журнал”, а время от времени его читать, замечать повторяющиеся ошибки и работающие решения.
Риски и подводные камни ИИ
Мы осветили основные причины использовать нейросети в улучшении своего рыночного анализа и навыков торговли. Теперь поговорим о подводных камнях и рисках работы с нейронками — их можно перечислять долго, а для трейдеров их важность умножается на размер депозита.
Начнём с самой базовой вещи, которую важно зафиксировать сразу. Языковая модель по своей природе ничего не “знает”. Она не имеет органов чувств и интуиции, какого-либо субъективного опыта. Её задача — написать текст так, чтобы он выглядел логично и статистически уместно в контексте вашего запроса. По сути, она просто выдумывает ответ, который выглядит статистически вероятным на основе тех данных, на которых была обучена. Нейронка фактически всё время что-то додумывает (галлюцинирует) — даже в тех случаях, когда ее заявления попадают в точку и соответствуют объективной реальности. “Правдивость” здесь не базовое свойство и далеко не гарантия, а скорее удачное совпадение. Когда ответ находится на грани между тем, что вы спросили, тем, какие данные предоставили, и тем, как модель это сформулировала на основе своей базы данных. Поэтому первый урок — всё сказанное нейросетью надо при возможности проверять.
Читая любой ответ ИИ, полезно сразу разбирать его по слоям. Где здесь обычный пересказ ваших же данных? Где интерпретация? Где предположение? А где откровенное заполнение пробелов (та самая галлюцинация)? Всё, что можно проверить цифрами, графиком, логом или источником данных, вы проверяете. Всё, что нельзя быстро проверить, автоматически помечаете как гипотезу — даже если звучит убедительно. А все гипотезы от нейронки вы автоматически ставите под сомнение. И дальше мы разберем, почему так стоит делать.
Самый частый и самый дорогой риск работы с нейронкой — это полное доверие к ней. LLM-ка почти всегда выдаёт связный, уверенный текст — даже если входные данные неполные, устаревшие или и вовсе неверные. Из-за этого велик соблазн воспринимать любые ее заявления как “серьезный анализ”. Как результат, у вас наступает внутренне облегчение: будто ситуация стала яснее. Вместо того, чтобы самостоятельно формировать и проверять гипотезы, вы начинаете подстраивать своё решение под красиво написанный вывод от ИИ. Особенно актуально — и опасно — это в моменты неопределённости, когда хочется, чтобы кто-то снял внутреннее напряжение готовым ответом.
Есть в обработке данных такое понятие “garbage in — garbage out”. То есть, плохие данные на входе = плохие данные на выводе. В трейдинге это правило работает особенно жёстко, ведь на кону стоит капитал. Если указать не тот таймфрейм, перепутать контекст, передать набор неплоных метрик или искаженных фактов — модель всё равно ответит, и ответ будет выглядеть разумно. Проблема в том, что нейронки не умеют стабильно и честно говорить “данных недостаточно/данные сомнительны/неверны”. Она всегда будет достраивать картину и выдумывать — лишь бы сочленить стройный, статистически вероятный ответ. В итоге вы можете получить идеально оформленные выводы, которые будут в корне неверны — и, если поверить им, приведут к печальным последствиям.
Есть и чисто технические риски, как правило связанные с перегрузом данными — так называемый “оверлёрнинг”. Как только вы ставите на поток алёрты, сложные правила и агентные цепочки, в игру вступают логические ошибки, баги, сбои API, лимиты запросов и неожиданные конфликты между источниками данных. Самое неприятное здесь то, что сама система может работать стабильно и без сбоев — но из-за перегруза данными она будет все время выдавать “что-то не то”. В таком режиме вы можете довольно долго не замечать, что читаете рынок и торгуете по “брехливому телефончику”. Поэтому, если автоматизируете свои стеки через API со множеством источников данных, стоит проводить регулярные проверки качества данных на выводе.


